Hadoop 架构
Hadoop 的优点:
-
存储和处理数据具有高可靠性。
-
通过分布式集群分配数据,具有高扩展性。
-
可以在节点间动态的移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。
-
能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop 的缺点:
-
不适用低延迟数据访问。
-
不能高效存储海量小文件。
-
不支持多用户写入并任意修改文件。
HDFS
HDFS (Hadoop Distribute File System) 是一个高可靠、高吞吐量的分布式文件系统,采用 Master/Slave 架构:

NameNode(NN):集群的 Master 节点,负责存储文件的元数据,例如文件名、目录结构、文件属性(创建时间、副本数、权限)等,以及每个块列表所在的 DateNode 等。
SecondaryNameNode(2NN):辅助 NameNode 更好的工作,用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据快照。
DataNode(DN):集群的 Slave 节点,负责在本地文件系统存储文件块数据,以及块数据的校验。
MapReduce
MapReduce 是一个分布式的离线并行计算框架:

Yarn
Yarn 是负责作业调度和集群资源管理的框架。

*注:图中紫色部分为一个任务流程,蓝色部分为另外一个任务流程。
ResourceManager(RM):在整个集群中承担 Master 的角色。它负责整个系统的资源管理和分配,包括客户端请求、启动/监控 ApplicationMaster、监控 NodeManager、资源的分配调度。内部主要有两个核心组件:
-
Scheduler: 一个可插拔的插件。当 Clien 提交一个任务时,它会根据任务所需资源和集群当前资源状况进行分配。要注意的是 Scheduler 只进行资源分配,并不对任务的执行情况进行监控。
-
ApplicationsManager: 主要负责接收提交的作业、协商启动第一个 Contaniner 来执行特定 Application 对应的 ApplicationMaster、监控 ApplicationMaster 的运行状态,并在其失败后重新启动它等。
ApplicationMaster(AM):每当 Client 提交一个 Application,就会初始化一个 ApplicationMaster,ApplicationMaster 负责向 Scheduler 申请适当的资源创建 Contaniner,随后将要运行的程序发送到该 Container 上启动,进行分布式计算。在此过程中,ApplicationMaster 还要时刻跟踪作业的状态并监视进度。是不是有些费解,为什么要把应用程序分发到容器上运行呢?在传统系统架构中,数据可以在各个应用中轻松流转,但是到了大数据的范畴,海量数据移动带来的成本是难以接受的,正所谓山不向我走来,我便向山走去,既然数据难以移动,我就让应用程序流动起来,只有真正理解这一点,你才能更好的理解大数据的架构。
NodeManager(NM):在整个集群中承担 Slave 的角色。它负责监控每台机器上物理资源(cpu、memory、disk、network)的使用情况以及向 ResourceManager/Scheduler 上报这些内容。
以紫色任务为例,客户端任务提交流程如下:
-
Client 向 ResourceManager 提交一个 Application。
-
ResourceManager 向有空闲资源的 NodeManager 发出指令为 Application 分配第一个容器,并在这个容器内启动该应用对应的 ApplicationMaster。
-
ApplicationMaster 启动后将作业(也就是 Application)拆分成若干个 Task,这些 Task 可以运行在一个或多个容器中,然后向 ResourceManager 申请要运行程序的容器,并定时向 ResourceManager 发送心跳。
-
申请到容器后,ApplicationMaster 会去和容器对应的 NodeManager 通信,而后将作业分发到对应的 NodeManager 中的容器去运行,这里会将拆分后的 MapReduce 进行分发,对应容器中运行的可能是 Map 任务,也可能是 Reduce 任务。
-
容器中运行的任务会向 ApplicationMaster 发送心跳,汇报自身情况。当程序运行完成后, ApplicationMaster 再向 ResourceManager 注销并释放容器资源。
集群搭建
集群规划

安装准备
在三台机器上均准备以下内容:
- Java
install.sh shell
yum -y install java-1.8.0-openjdk java-1.8.0-openjdk-devel echo "export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.el7_9.x86_64" >> ~/.bashrc source ~/.bashrc
- Hadoop
code shell
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz --no-check-certificate -O /download/hadoop-3.3.1.tar.gz tar -xvf hadoop-3.3.1.tar.gz -C /opt/
验证:
[root@dell /]# /opt/hadoop-3.3.1/bin/hadoop version Hadoop 3.3.1 Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2 Compiled by ubuntu on 2021-06-15T05:13Z Compiled with protoc 3.7.1 From source with checksum 88a4ddb2299aca054416d6b7f81ca55 This command was run using /opt/hadoop-3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar [root@dell /]# echo $JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-1.el7_9.x86_64 [root@dell /]# java -version openjdk version "1.8.0_312" OpenJDK Runtime Environment (build 1.8.0_312-b07) OpenJDK 64-Bit Server VM (build 25.312-b07, mixed mode) [root@dell /]# javac -version javac 1.8.0_312
HDFS 配置
Hadoop 的配置均在
/opt/hadoop-3.3.1/etc/hadoop目录下,下文 shell 环境当前目录均为此目录。
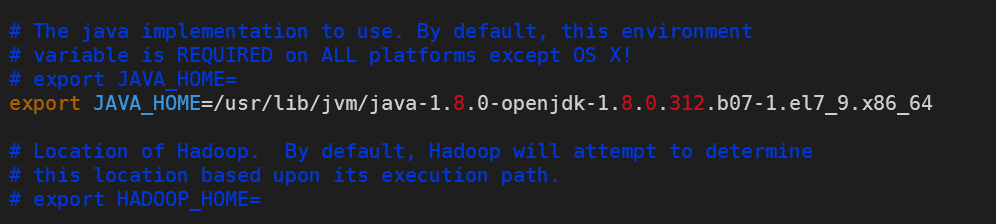
- 配置所使用的 JDK 路径
因为在上一节安装 java 的时候已经配置了环境变量 JAVA_HOME,所以此步骤可以省略,但如果你需要指定另外的 jdk 给 hadoop 使用,则需要编辑 hadoop-env.sh 指定路径。
vi hadoop-env.sh
- 指定 NameNode 节点以及存储目录
mkdir -p /data/hadoop
<configuration> <!-- 指定 HDFS 集群 NameNode 地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.8.9:9000</value> </property> <!-- 指定 Hadoop 运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop</value> </property> </configuration>
- 指定 SecondaryNameNode 节点
<configuration> <!-- 指定 HDFS 集群辅助节点 SecondaryNameNode 地址 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.8.60:50090</value> </property> <!-- 副本数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration>
- 指定 DataNode 节点
192.168.8.8 192.168.8.9 192.168.8.60
MapReduce 配置
# 在 hadoop-env.sh 最后追加 Hadoop 路径 echo export HADOOP_HOME=/opt/hadoop-3.3.1 >> hadoop-env.sh
<configuration> <!-- 指定 MapReduce 运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史记录服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.8.9:10020</value> </property> <!-- 历史记录服务 web 地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.8.9:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> </configuration>
Yarn 配置
<configuration> <!-- 指定 Yarn 集群的 ResourceManager 地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.8.9</value> </property> <!-- Reduce 获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 日志地址 --> <property> <name>yarn.log.server.url</name> <value>http://192.168.8.9:19888/jobhistory/logs</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志保留 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
格式化 NameNode
只有在集群第一次启动时才需要格式化操作!!!之后千万不要再重复执行!!!
bin/hadoop namenode -format
格式化成功后目录结构如下:
[root@dell hadoop-3.3.1]# tree /data/hadoop
/data/hadoop
└── dfs
└── name
└── current
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
3 directories, 4 files
单独启动
[root@dell hadoop-3.3.1]# bin/hdfs --daemon start namenode [root@dell hadoop-3.3.1]# bin/hdfs --daemon start datanode [root@dell hadoop-3.3.1]# bin/yarn --daemon start resourcemanager [root@dell hadoop-3.3.1]# bin/yarn --daemon start nodemanager [root@dell hadoop-3.3.1]# jps 26673 Jps 23366 ResourceManager 4634 DataNode 4349 NameNode 26542 NodeManager
[root@nuc hadoop-3.3.1]# bin/hdfs --daemon start datanode [root@nuc hadoop-3.3.1]# bin/yarn --daemon start nodemanager [root@nuc hadoop-3.3.1]# jps 1673 NodeManager 362 DataNode 1852 Jps
[root@g4 hadoop-3.3.1]# bin/hdfs --daemon start secondarynamenode [root@g4 hadoop-3.3.1]# bin/hdfs --daemon start datanode [root@g4 hadoop-3.3.1]# bin/yarn --daemon start nodemanager [root@g4 hadoop-3.3.1]# jps 7649 NodeManager 9842 Jps 6119 DataNode 9785 SecondaryNameNode
群起
群起是 Hadoop 脚本通过 ssh 将命令批量发送至各个节点进行启动的,所以在群起之前需要保证各个节点可以通过 ssh 正常访问。
在启动前还需对群起脚本进行简单配置:
# ssh 连接端口号,默认会使用 22 export HADOOP_SSH_OPTS="-p 1234 -o BatchMode=yes -o StrictHostKeyChecking=no -o ConnectTimeout=10s" # 各个节点 ssh 登录的用户 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root
配置完成后,使用脚本启动即可:
# 启动集群 sbin/start-all.sh # 停止集群 sbin/stop-all.sh
启动历史记录服务
[root@dell hadoop-3.3.1]# bin/mapred --daemon start historyserver [root@dell hadoop-3.3.1]# jps 12562 Jps 419 DataNode 2116 NodeManager 1349 ResourceManager 12470 JobHistoryServer 32298 NameNode
验证
集群启动后,可以通过 webui 查看集群当前状态,webui 部署在 NameNode 所在节点的 9870 端口:
如需使用其它端口,可修改
etc/hadoop/yarn-site.xml文件,新增dfs.namenode.http-address为0.0.0.0:xxxx即可。
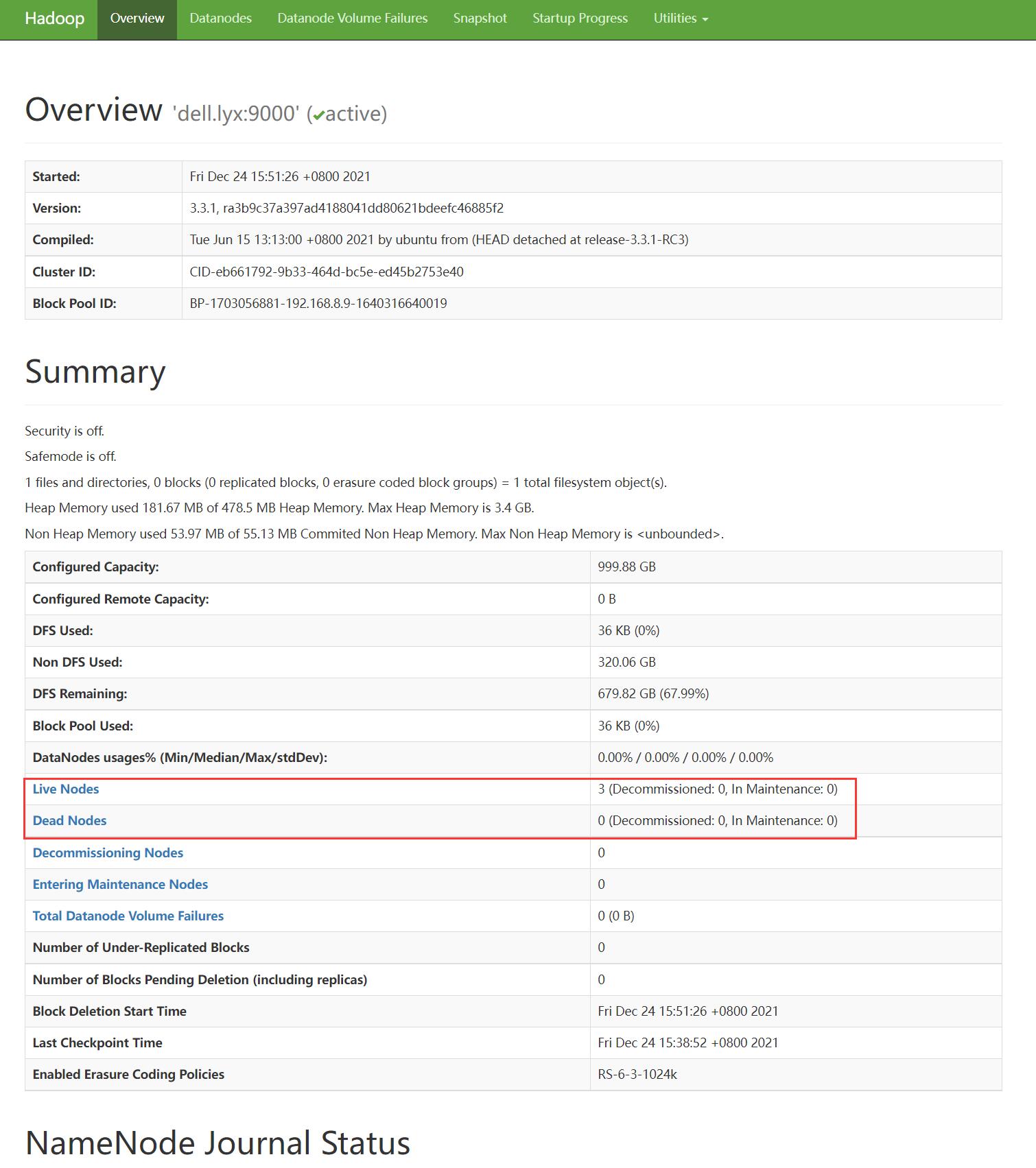
注意图中红色框选位置,Live Nodes 应为 3,Dead Nodes 应为 0。
webui 还提供了 HDFS 文件系统的可视化界面,在此界面可以对文件系统进行简单的操作,例如创建文件夹、上传下载文件等:
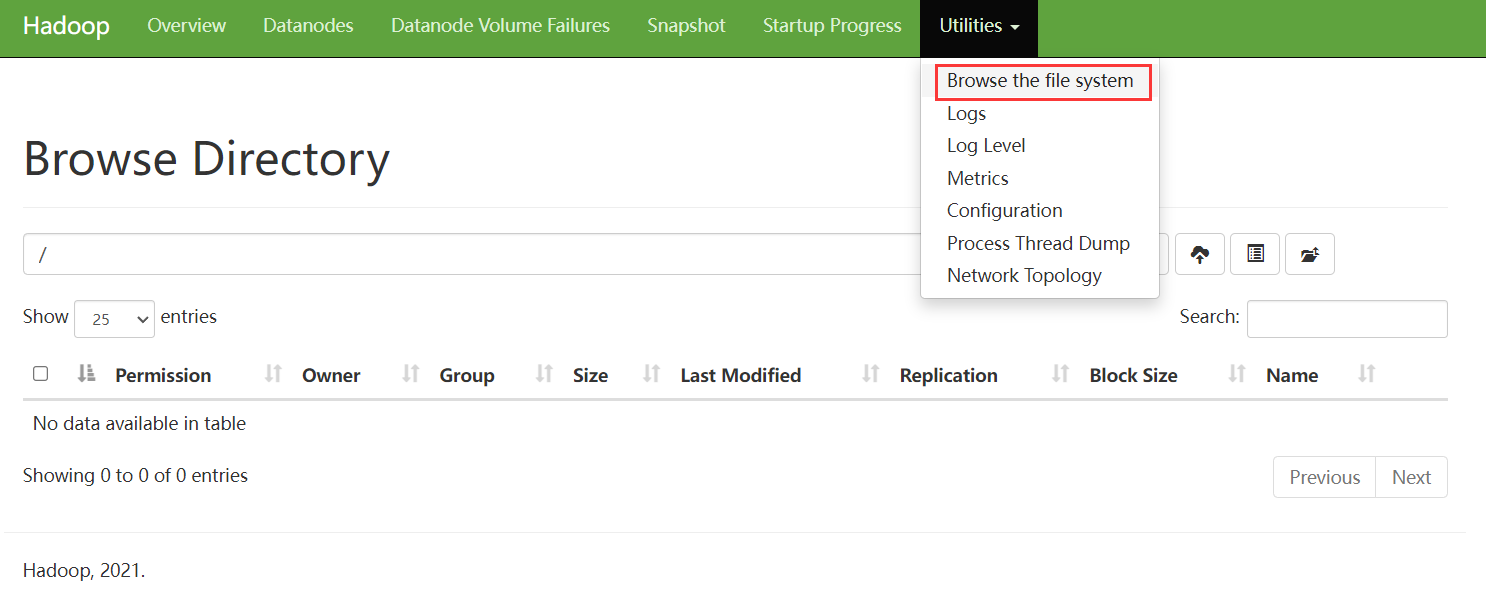
当然 HDFS 也可以通过命令行进行操作,操作命令与本地文件系统常用命令基本一致:
[root@dell hadoop-3.3.1]# bin/hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum [-v] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-concat <target path> <src path> <src path> ...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] [-s] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate] [-fs <path>]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP (yyyyMMdd:HHmmss) ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
后续内容省略.....
递归创建文件夹:
bin/hdfs dfs -mkdir -p /fangjin/txt
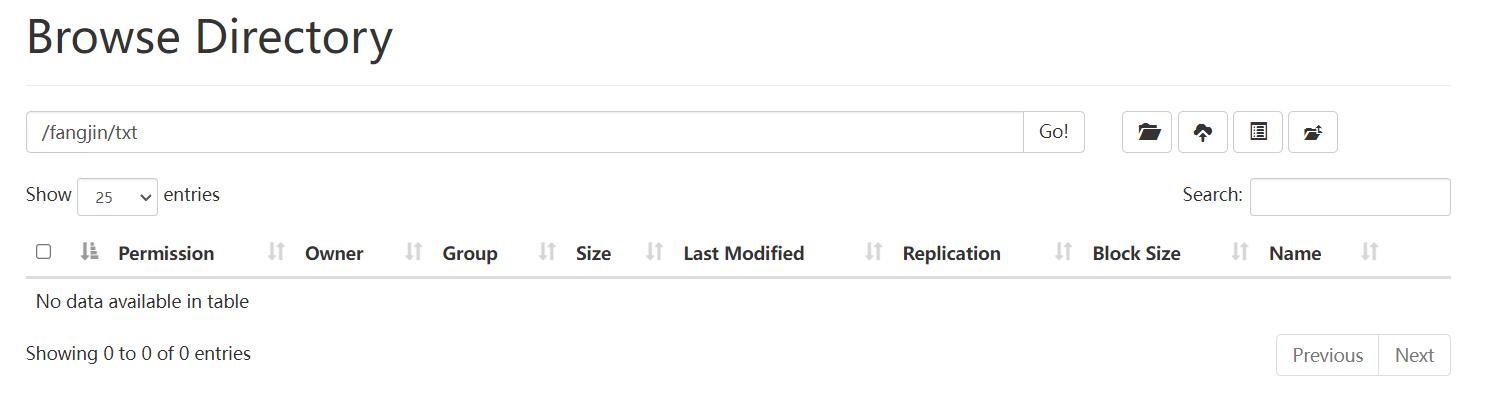
上传文件:
echo hello world! > /hello.txt bin/hdfs dfs -put /hello.txt /fangjin/txt
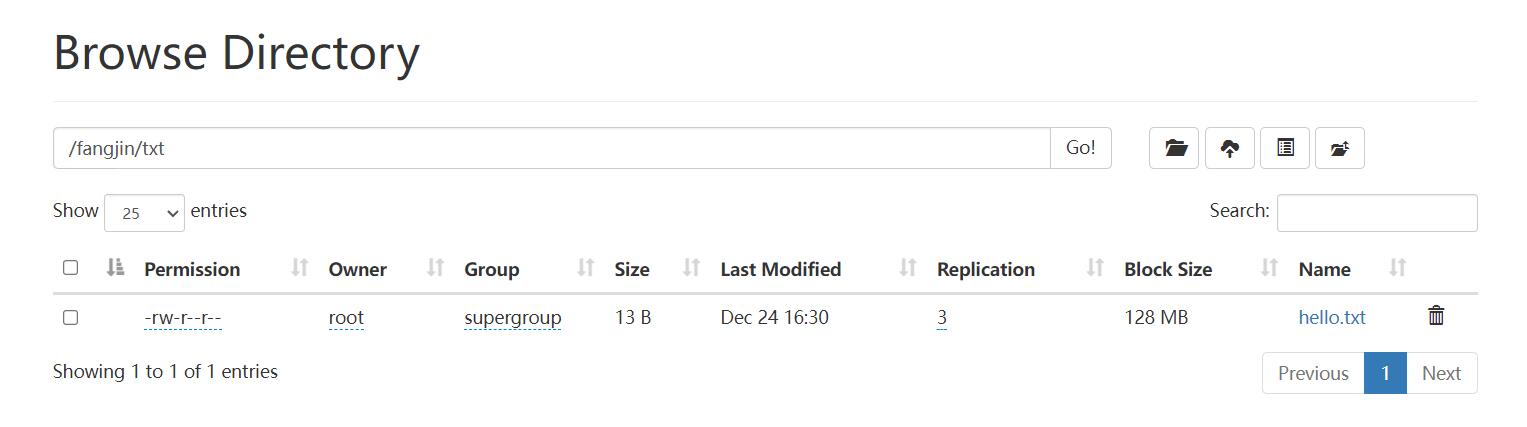
下载文件:
[root@dell hadoop-3.3.1]# bin/hdfs dfs -get /fangjin/txt/hello.txt ./hh.txt [root@dell hadoop-3.3.1]# cat hh.txt hello world!
分布式计算初体验:
Hadoop 官方提供了一个 WordCount 的示例用来统计一段文本中每个单词出现的次数,首先我们需要准备一个文件并上传到 HDFS 中:
# 将 hdfs 的帮助文档写入文件 bin/hdfs dfs -help > /hdfs-help.txt # 上传到一个已存在的目录 bin/hdfs dfs -put /hdfs-help.txt /fangjin/txt # 执行示例 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /fangjin/txt /wordcount-output # 打印结果 bin/hdfs dfs -cat /wordcount-output/part-r-00000
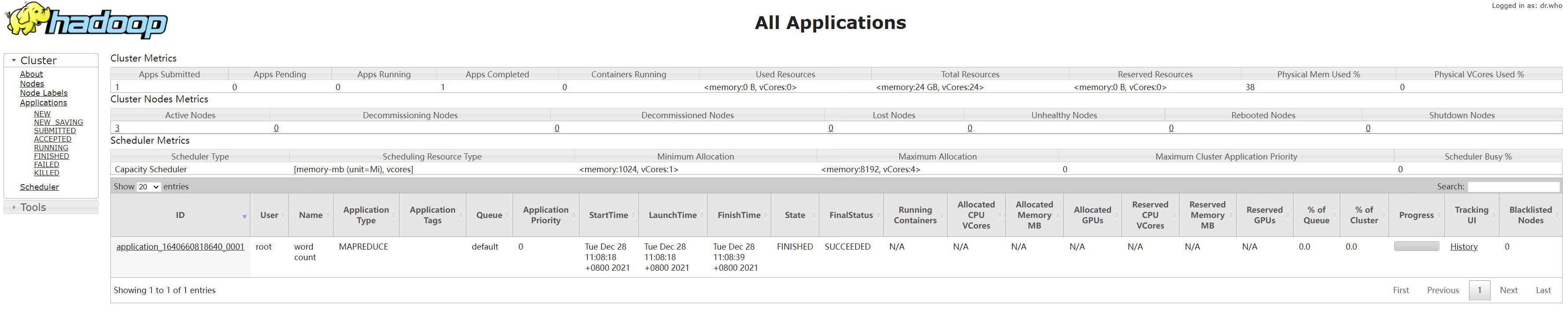
通过 webui 查看任务执行日志:
Yarn 集群的 ResourceManager 对外暴露了 8088 端口,浏览器访问 http://192.168.8.9:8088 可以查看历史任务日志: